SEO en crawlers, SEO en rastreadores online
Crawler o Spider es un script que se utiliza para recopilar información de todas las páginas web disponibles en Internet. El propósito básico de los rastreadores es recopilar información en una página e indexarla en la base de datos para su posterior recuperación. Pero hay muchos tipos de rastreadores que se utilizan para múltiples propósitos, tanto para bien como para mal. Los proveedores de buscadores les dan un nombre para facilitar la comprensión, como Googlebot o Bingbot. Por ejemplo, Google tiene muchos rastreadores como se indica a continuación:
- Googlebot: indexa el contenido para mostrarlo en los resultados de búsqueda web.
- Googlebot-Image: indexa las imágenes para mostrarlas en los resultados de búsqueda de imágenes
- Googlebot-News: recopila noticias para mostrar en los resultados de búsqueda de noticias.
- Googlebot-Video: rastrea videos en la web y los muestra en los resultados de búsqueda de videos
- Googlebot-Mobile: rastreador para búsqueda móvil
- Mediapartners-Google: rastreador de Google AdSense
Estos rastreadores navegan por la web e indexan contenido nuevo en la base de datos del motor de búsqueda. Cuando un usuario busca una consulta, el contenido de la base de datos se recupera basándose en algoritmos sofisticados.
Por otro lado, muchos bots se utilizan para recopilar información con fines de piratería.
☑ ¿Cómo conocer el rastreador? Conociendo el crawler
Los buscadores proporcionan herramientas para webmasters o una cuenta de Search Console para ver y controlar las actividades del rastreador en su sitio si esto afecta el rendimiento. Además de esto, todas las entradas del rastreador se pueden obtener del registro del servidor del sitio para fines de análisis y resolución de problemas. Por ejemplo, si ve un robot defectuoso rastreando su sitio, puede bloquear ese en particular para salvaguardar el contenido del sitio.
En caso de que el rastreador afecte las actividades del usuario en el sitio, puede controlar la frecuencia y el tiempo de rastreo desde la cuenta de Herramientas para webmasters de tal manera que el rastreo se pueda realizar fuera de las horas pico sin afectar a los usuarios.
Los propietarios del sitio deciden si un rastreador debe seguir una página web o no agregando los atributos adecuados en la sección de encabezado mediante metaetiquetas de robots o mediante un archivo robots.txt en el directorio raíz. El atributo de agente de usuario en el archivo robots.txt se usa para especificar el nombre del bot para permitir o denegar el acceso a una página, directorio o sitio completo específico. Por ejemplo, si no desea que el rastreador de Google escanee su sitio, utilice el siguiente código para denegar el acceso:
User-agent: Googlebot
Disallow: /
Aunque es posible indicar a los rastreadores que sigan las metaetiquetas robots.txt o robots, depende de los rastreadores obedecer estas reglas. Generalmente, los buscadores siguen esto, pero los robots malos no lo hacen.

☑ Informar a los rastreadores a través de Robots.txt y etiqueta Nofollow
Crawler o Spider es un script que se utiliza para recopilar la información de todas las páginas web disponibles en la web. Los proveedores de motores de búsqueda les dan un nombre para facilitar la comprensión, como Googlebot o Bingbot. La parte importante es que usted, como propietario de su sitio, debe decirles a estos rastreadores cuáles son los enlaces URL que se van a indexar y cuáles son los enlaces de referencia de su sitio que el buscador debe considerar.
☑ ¿Qué es Robots.txt?
Un «robots.txt» es un archivo de texto en el directorio raíz de cada página web que informa a los buscadores si la página web puede ser rastreada o no. Este es un archivo opcional que se usa solo si tiene que dar instrucciones a los rastreadores y la mayoría de los sistemas de administración de contenido generan automáticamente el archivo robots.txt. Simplemente puede ingresar «www.tuweb.com/robots.txt» en la barra de direcciones del navegador para ver el archivo robots.txt de su sitio.
Algunas de las páginas de su sitio pueden contener información confidencial y, si no evita que los motores de búsqueda dejen de rastrear esas páginas utilizando el archivo robots.txt, todos esos detalles confidenciales se mostrarán al público en los resultados de la búsqueda. Además de ocultar páginas de los buscadores, el archivo robots.txt también se utiliza para saber qué se espera que haga exactamente un robot de búsqueda en un sitio.
Por ejemplo, puede evitar que Googlebot acceda solo a un directorio específico en su sitio y detener / proporcionar el acceso completo a Bingbot.
1. Google Search Console ofrece un generador de archivos robots.txt para ayudarlo a crear este archivo que puede cargar en su servidor.
2. Se recomienda tener un archivo robots.txt vacío incluso si no desea dar instrucciones a los rastreadores.
☑ ¿Es suficiente usar Robots.txt para ocultar información confidencial?
Definitivamente no es una forma muy segura de ocultar su contenido sensible de los buscadores simplemente usando robots.txt por las siguientes razones:
- Como cualquiera puede ver el archivo robots.txt en el navegador, algún usuario curioso puede intentar analizar los directorios y juzgar las URL que está ocultando.
- Algunos robots de buscadores no siguen la exclusión de robots.txt y continúan indexando sus páginas confidenciales.
- Los motores de búsqueda seguirán mostrando la URL bloqueada en los resultados de búsqueda.
Obtenga más información sobre el archivo robots.txt .
☑ Usando .htaccess
El acceso de hipertexto o .htaccess es un archivo de configuración más compatible que se utiliza para controlar un directorio particular de un servidor web. Se utiliza para controlar el comportamiento de un sitio individual en un servidor, aunque el servidor tiene su propia configuración global. Este es el archivo que generalmente se usa para controlar las autorizaciones necesarias para acceder a cualquier parte particular del sitio.
Por ejemplo, puede bloquear una dirección IP o un dominio específicos para que no acceda a su sitio. También puede establecer reglas de redireccionamiento para informar a los motores de búsqueda cuando acceden a una página en particular.
Generalmente, las cosas más seguras se controlan directamente a nivel de configuración del servidor mediante el archivo http.conf.
Comprender rel = «nofollow» para enlaces
Google introdujo un mecanismo de PageRank que evalúa una página en función de los enlaces externos. Más tarde, esto fue seguido por la mayoría de los otros motores de búsqueda y cambió todo el juego de la optimización de buscadores. La mayoría de los webmasters y las empresas de SEO comenzaron a crear enlaces artificiales solo para mejorar la clasificación del sitio en los resultados de búsqueda. Para garantizar la calidad de los enlaces externos, Google volvió a introducir el atributo de enlace HTML rel = ”nofollow” para indicar a los rastreadores de los buscadores si deben considerar el enlace al evaluar el ranking de búsqueda.
A continuación se muestra la sintaxis de cómo se utiliza el atributo «nofollow»:

Agregar enlace sin seguimiento
☑ ¿Dónde puedo usar Nofollow?
Rel = ”nofollow” es un atributo de enlace HTML que se utiliza en las etiquetas de anclaje para informar a los rastreadores de los motores de búsqueda que no tengan en cuenta el enlace al evaluar la clasificación de búsqueda. Este método fue inicialmente encontrado por Google y luego adoptado como estándar seguido por otros buscadores como Bing.
El algoritmo de búsqueda de Google depende en gran medida del peso del enlace externo de una página, lo que hace que los webmasters envíen spam a otros sitios con sus enlaces para mejorar el rango de búsqueda de su sitio. Uno de los principales objetivos de los robots de spam son los comentarios del blog, donde es fácil dejar un comentario con un enlace, ya que la mayoría de los propietarios del sitio aprueban automáticamente los comentarios en días anteriores. Para superar este spam de comentarios, Google introdujo un mecanismo para agregar una etiqueta «rel =» nofollow «» para cualquier hipervínculo individual para evitar considerar ese vínculo al calcular el PageRank para los resultados de búsqueda.

Sintaxis
El atributo Nofollow se utiliza dentro de una etiqueta de anclaje HTML como se muestra a continuación:
<a href= "http://example.com" rel="nofollow"> Este es un enlace nofollow, no envíe spam </a>
El atributo Nofollow se utiliza para informar a los buscadores que no se deben seguir todos los enlaces de una página, mientras que rel = ”nofollow” se utiliza para enlaces específicos, lo que proporciona más control a los webmasters.
Nofollow se puede utilizar en muchos casos, aquí te dejamos algunos de los casos importantes:
- Esto es muy útil para evitar enlaces de sitios con spam ingresados en la sección de comentarios de su blog, ya que la sección de comentarios del blog es muy vulnerable al spam de comentarios como el que se muestra a continuación.
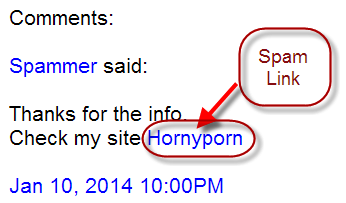
Ejemplo de spam de comentarios
- Al usar el atributo No-follow en rel en los enlaces en los comentarios, se confirma que no le está dando la reputación de su página a un sitio con spam.
- Nofollow también será útil en foros, libros de visitas y tableros de anuncios. La mayoría de los proveedores de blogs y foros agregan nofollow a los comentarios de los usuarios de forma predeterminada para evitar agregarlo manualmente en cada comentario por separado.
- También puede usar la moderación de comentarios, como ingresar el código CAPTCHA y usar el inicio de sesión de la red social para comentar.
- Nofollow también puede ser útil cuando se refiere a un enlace en su sitio, pero no está interesado en transmitirle la reputación de su enlace saliente.
- Si desea no seguir todos los enlaces en cualquiera de las páginas de su sitio, use «nofollow» en su metaetiqueta robots, que se coloca dentro de la etiqueta <head> del HTML de esa página, como se muestra a continuación:

No seguir todos los enlaces de una página
Limitaciones
- No todos los motores de búsqueda interpretan este atributo de la misma manera.
- Depende de los rastreadores obedecer este atributo o no.
- Los enlaces nofollow se seguirán si los buscadores los encuentran a través de un sitio o página diferente que enlaza con la página nofollow.
☑ Metaetiquetas de robots
Las metaetiquetas de robots son etiquetas HTML que se utilizan dentro de la sección <head> de una página web para informar a los rastreadores de los buscadores si la página debe indexarse y los enlaces de la página deben seguirse o no. El nombre robots indica que estas etiquetas se utilizan para guiar robots o rastreadores y no para los usuarios humanos.
Las metaetiquetas de robots tienen los siguientes dos atributos:
- «Nombre», que siempre debe mencionarse como «robots» y
- «Contenido», que deberá tener uno de los cuatro parámetros siguientes según la necesidad:
- Index: permitido indexar
- Noindex: no se permite indexar
- Follow: se permite seguir los enlaces de esa página.
- Nofollow: no se permite seguir enlaces en esa página
Sintaxis
Las metaetiquetas de robots se utilizan de la siguiente manera:
<HTML> <HEAD> <TITLE> Título de la página </TITLE> <META NAME = "ROBOTS" CONTENT = "NOINDEX, FOLLOW"> <META NAME = "ROBOTS" CONTENT = "INDEX, NOFOLLOW"> <META NAME = "ROBOTS" CONTENT = "NOINDEX, NOFOLLOW"> </HEAD>
Si no se mencionan etiquetas de robots, los valores “INDICE, FOLLOW” se considerarán por defecto.
Los rastreadores tienen prioridad sobre el archivo robots.txt cuando se utilizan metaetiquetas de robots en combinación con el archivo robots.txt. Por lo tanto, permitir un directorio en el archivo robots.txt y usar noindex en la metaetiqueta para restringir una página dentro del mismo directorio no tendrá ningún impacto en los rastreadores.
- Aunque todos los robots de los motores de búsqueda siguen las condiciones definidas en Robots Meta Tags, los rastreadores deben decidir si obedecer o no.
- Generalmente, los malwares que rastrean la web no siguen estas etiquetas, por lo tanto, las metaetiquetas de Robots no son la forma de ocultar información confidencial de los buscadores, sino que utilizan contraseñas del lado del servidor para restringir el acceso.
- El atributo Nofollow no tiene un valor real cuando la página tiene muchos enlaces internos o externos. Los buscadores encontrarán el enlace de la página desde otros sitios u otras páginas y seguirán el contenido de la página nofollow.
